HashMap
概念
用于存储Key-Value键值对(entry)的集合,每一个键值对也叫做entry,这些entry分散存储在一个数组中,这个数组就是HashMap的主干。
每一个元素(entry)的初始值都是null

最常用的get和put方法。
put方法原理
调用hashMap.put("beauty",0),插入一个key为"beauty"的元素
- index = hashcode("beauty")&(hashMap.size-1)
假定最后得出的index为2
- 但是当插入的entry越来越多,难免会出现index冲突的现象
HashMap的数组每一个元素不止是一个entry对象,是一个链表的头节点,entry对象可以通过next指针指向它的下一个entry节点,当新插入的entry遇到冲突的数组位置时,直接插入到对应的链表即可:
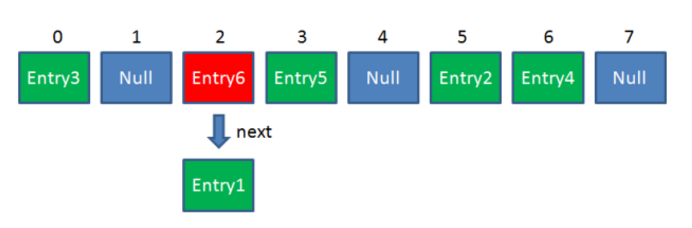
java8中当链表长度超过8,会直接变成红黑树
采用的是“头插法”,HashMap创造者认为,后插入的元素被查找的可能性大。
get方法
- 首先根据输入的key做一次hash映射,得到index index = hashcode(key)&(hashMap.size()-1)
- 同一个位置上有可能匹配到多个entry, 这个时候需要顺着链表的头节点一个一个向下找
初始化长度
初始化长度为16,后面增长 长度是2的幂
哈希函数
index = hashcode(key)&(size-1)
例:计算book的index
1.计算hashcode-十进制3029737,二进制101110001110101110 1001
2.hashmap初始化长度16,计算length-1为十进制15,二进制1111
3.以上两个值做&运算
101110001110101110 1001 &
1111
-------------------------
1001
对应的十进制9,所以index = 9
index结果取决于key的hashcode的最后几位
长度为16或其它2的幂,length-1的二进制位全为1,这种情况下与key的hashcode做&运算的结果等同于hashcode的后几位的值,只要输入的hashcode本身均匀,hash算法的结果就是均匀的。
高并发下的HashMap
Hashmap的容量是有限的,达到容量的时候需要扩容,resize
是否进行resize的条件如下
HashMap.size()>=CapacityLoadFactor
Capacity:HashMap的当前长度,Hash的长度是2的幂
LoadFactor:HashMap负载因子,默认是0.75f
resize做了两件事情:
1.扩容
创建新的数组长度是原来的两倍
2.Rehash
*为什么要rehash,因为长度发生变化后,规则也随之发生变化,计算index的那个方法。
HashMap是非线程安全的
rehash在并发的情况下可能会出现链表环,如何解决?,使用ConcurrentHashMap.
什么是ConcurrentHashMap?
ConcurrentHashMap是如何实现线程安全的,又是怎么实现搞笑读写的?
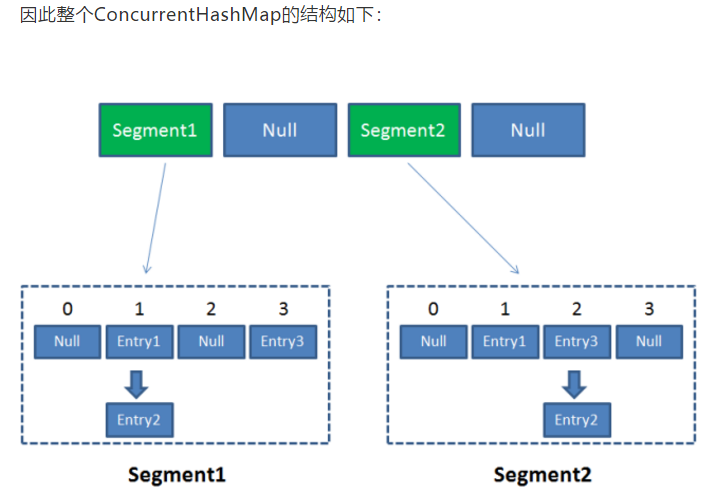
ConCurrentHashMap相当于一个二级Hash表,它的优势就是采用了锁分段技术,每个segment都是独立的,zegment之间互不影响。
segment写入是需要上锁的,同一个segment的写入是阻塞的,每个segment持有一把锁,保证线程安全的同时,降低了锁的粒度,让并发操作效率更高。
put和get原理
- get方法
- 输入的key做hash运算得到hash值
- 通过hash值定位到具体的segment对象
- 再通过hash值,定位到segment中数组的具体位置
- put方法
- 输入的key做hash运算得到hash值
- 通过hash值定位到具体的segment对象
- 获取可重入锁
- 再通过hash,定位到segment数组的具体位置
- 插入或者覆盖entry对象
- 释放锁 3.size计算原理
- 遍历所有的segment
- 将segment的元素数量累加起来
- 把segment修改次数累加起来
- 总修改次数是否大于上一次修改次数,如果大于则说明计算过程中有修改,重新统计,尝试次数+1,如果不是,说明没有修改,结束统计
- 重新次数超过阈值,对每一个segment加锁,重新统计
conCurrentHashMap在对key进行hash时,为了实现segment均匀分布,进行了两次hash
红黑树 (数据结构)
二叉树的特性
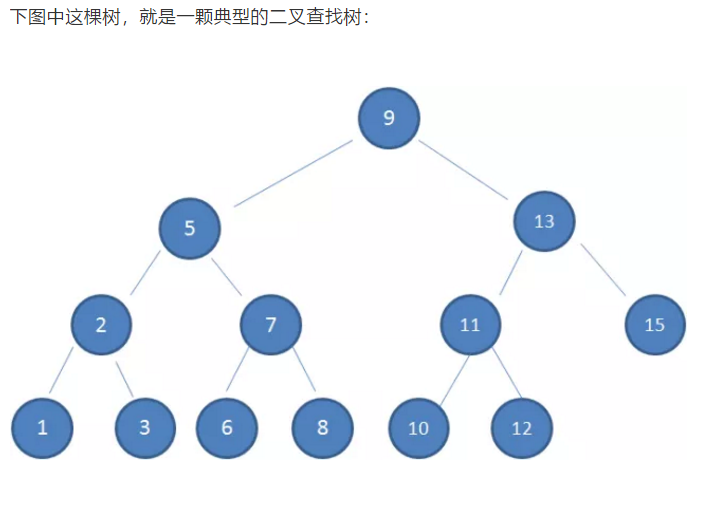
1. 左子树所有节点的值小于或者等于它的根节点的值
2. 右子树所有节点的值均大于或者等于根节点的值
3. 左右子树也分别为二叉排序树
例:查找10
1. 从根节点9开始找,由于10大于9,走到右孩子13
2. 由于10小于13走到左孩子11
3. 由于10小于11走到左孩子10,结束
二分查找思想,查找的最大次数等于二叉查找树的高度
插入节点也是利用相同的方法
二叉树的缺点:
例:8、9、10节点依次插入1、2、3、4、5、6,就变成如下:
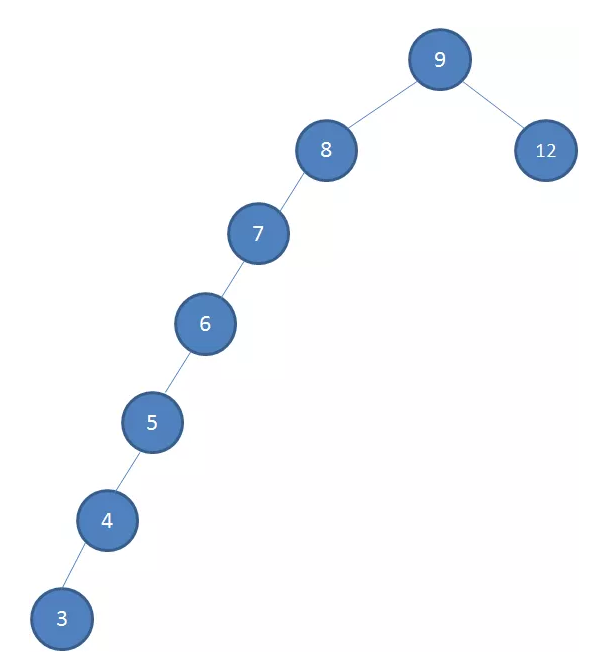
查找的性能大打折扣,几乎变成了线性
如何解决这种不平衡?红黑树
红黑树特性
- 节点是红色或者黑色
- 根节点是黑色
- 每个叶子节点都是空的黑色节点(null节点)
- 每个红色的两个子节点都是黑色(从每个叶子到根的所有路径不能有两个连续的红色节点)
- 从任一节点到叶子的所有路径都包含相同数目的黑色节点。
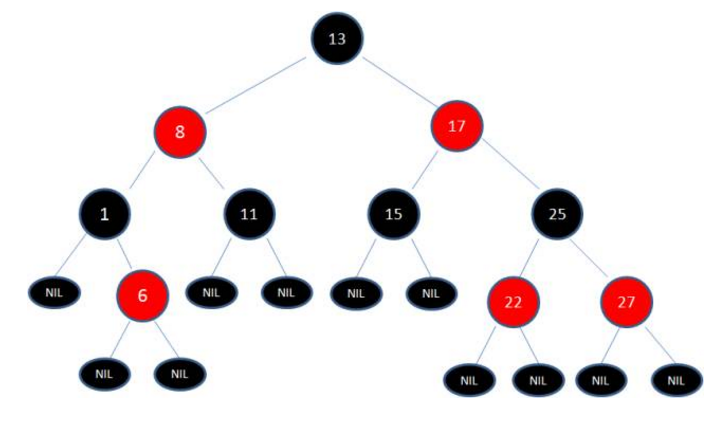
调整红黑树的两种方法(变色、旋转)
AES算法(对称加密算法)
MD5和sha256属于摘要算法,是不可逆的,主要的作用是对信息的一致性和完整性进行校验,对称加密算法可逆,保证私密信息不被泄漏。
三个基本概念(密钥、填充、模式)
- 密钥:AES支持三种密钥:128位、192位、256位,实际就是大家平时说的AES128\AES192\AES256。从安全性AES256最高,AES128性能最好,加密处理轮数不同。
- 填充
什么是分组加密?
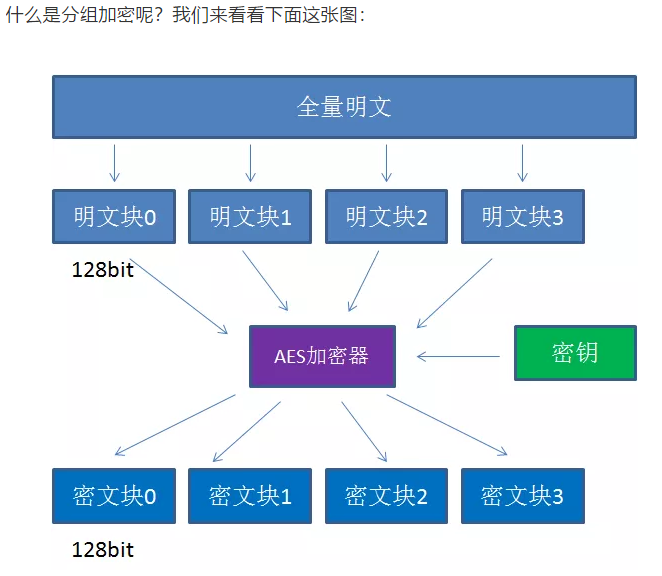
AES加密过程:- AES在对明文进行加密的时候并不是把整个明文一股脑的加密成一整段密文,而是把明文拆分成一个个独立的明文块,每个明文块的长度是128bit
- 这些铭文块经过加密器的复杂处理,生成一个个独立的密文块,这些密文块拼接在一起,就是最终的AES加密结果。
但是有个问题?加入一段明文是192bit,拆分后第二块只有64bit,不足128bit,这个时候就需要填充。
AES在不同的语言中有许多不同的填充算法,典型的几种:
NoPadding:不做任何填充,但是要求明文必须是16字节的整数倍。
PKCS5Padding(默认):如果明文块少于16个字节(128bit),在明文块尾端补足相应数量的字符,且每个字节的值等于缺少的字符数。
例:{1,2,3,4,5,a,b,c,d,e},缺少6个字节,则补全为{1,2,3,4,5,a,b,c,d,e,6,6,6,6,6,6}
ISO126Padding:如果明文块少于16字节(128bit),在明文块末尾不足相应数量的字节,最后一个字符值等于缺少的字符数,其它字符随机填充。
例:{1,2,3,4,5,a,b,c,d,e},缺少6个字节,则可能补全为{1,2,3,4,5,a,b,c,d,e,6,7,8,#,G,6}
注意:AES加密的时候用了某种填充方式,解密时也必须采用同样的解密方式。
- 模式
AES的工作模式,体现在把明文块加密成密文块的处理过程中,AES加密算法提供了五种不同的工作模式:ECB,CBC,CTR,CFB,OFB
模式之间的主体思想是近似的,处理细节上有些差别- ECB模式(默认)电码本模式Electronic CodeBook Book
- CBC 密码分组链接模式Cipher Block Chaining
- CTR 计算器模式 Counter
- CFB 密码反馈模式 Cipher FeedBack
- OFB 输出反馈模式 OutputFeedBack
同样在加密的时候使用某种工作模式,解密也必须采用相同的工作模式。
在java中的具体实现

注意:调用封装好的AES算法时,表面上使用的key并不是真正用于AES加解密的密钥,而是生成真正密钥的种子。填充明文时,如果明文的长度原本就是16字节的整数倍,除了Nopadding外,其它填充方式都会填充一组额外的16字节明文块。
AES算法的底层原理
一个字节由两个十六进制位表示,00~ff表示0~255,一个字节刚好也可表示0~255
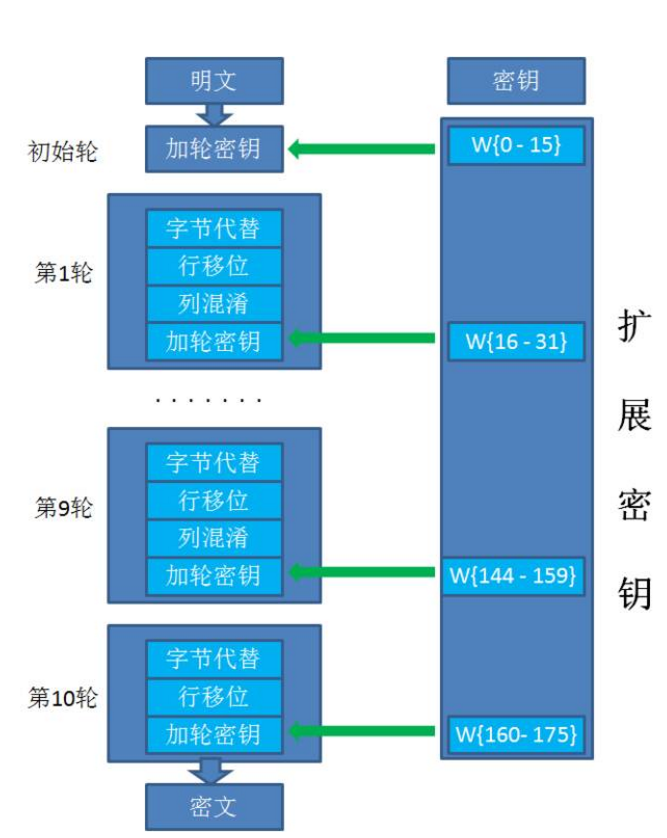
AES加密不是一次把明文加密成密文,而是经过很多轮的加密
具体需要多少论?》
初始轮 (Initial Round) 1次
普通轮 (Rounds) n次
最终轮 (Final Round) 1次
除去初始轮,各种Key长度对应的轮数如下:
AES128:10轮
AES192:12轮
AES256:14轮
不同阶段的Round有不同的处理步骤。
初始轮只有一个步骤:
加轮密钥(AddRoundKey)
普通轮有四个步骤:
字节代替(SubBytes)
行移位(ShiftRows)
列混淆(MixColumns)
加轮密钥(AddRoundKey)
最终轮有三个步骤:
字节代替(SubBytes)
行移位(ShiftRows)
加轮密钥(AddRoundKey)
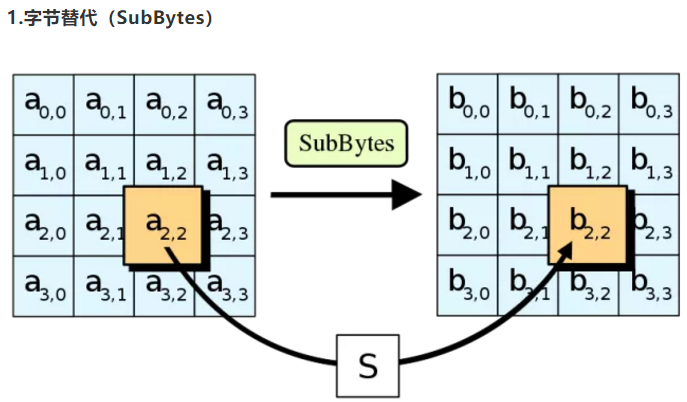
字节替代 subByte
十六字节的明文块在第一个处理步骤中被排列成一个4x4的二位数组,字节替代就是把明文块的每一个字节都替换成另外一个字节
替代的依据是通过一个S盒(subtitution Box)的16x16大小二维常量数组。
例如明文块a[2,2]=5B 一个字节是两位十六进制位,那么输出值b[2,2]=S[5,11]
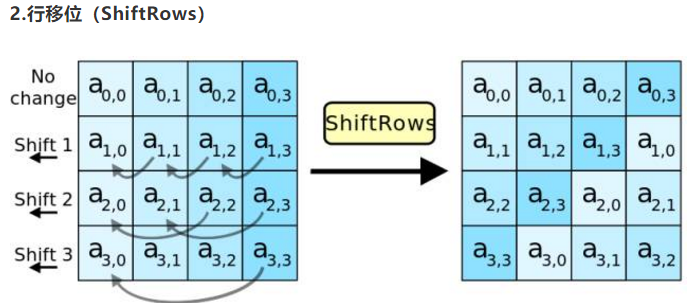
行移位 shiftRows
如图:
第一行不变
第二行循环左移一个字节
第三行循环左移两个字节
第四行循环左移三个字节
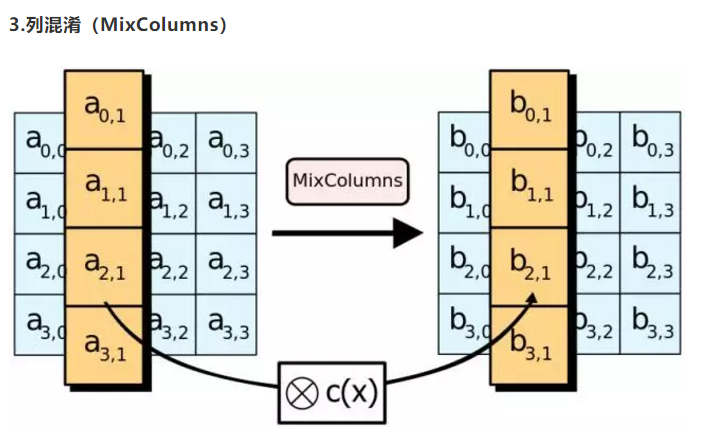
列混淆MixColumns
输入数组的每一列要和一个明文修补矩阵(fix matrix)的二位常量数组做矩阵相乘,得到对应的输出列
加 论密钥(add round key)
- 128bit的密钥同样被排列成4x4矩阵
- 输入数组的每一个字节a[i,j]与密钥对应位置的字节k[i,j]异或一次就生成了输出值b[i,j]
加密每一轮用到的密钥是不同的
扩展密钥(KeyExpentions)
AES源代码中用长度 4 * 4 *(10+1) 字节的数组W来存储所有轮的密钥。W{0-15}的值等同于原始密钥的值,用于为初始轮做处理。后续每一个元素W[i]都是由W[i-4]和W[i-1]计算而来,直到数组W的所有元素都赋值完成。W数组当中,W{0-15}用于初始轮的处理,W{16-31}用于第1轮的处理,W{32-47}用于第2轮的处理 ......一直到W{160-175}用于最终轮(第10轮)的处理。
不同工作模式在加密流程中有什么不同?
所有工作模式的差别都体现在宏观上,即明文块与明文块之间的关联,AES加密器的内部处理流程都是相同的。
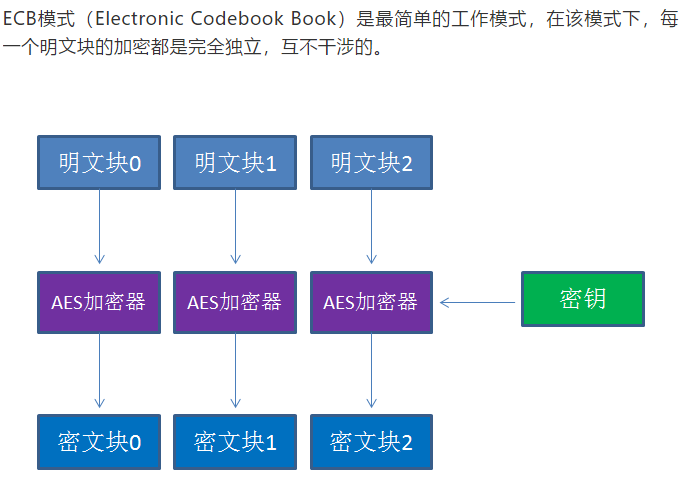
1. ECB模式(electronoc CodeBook Book)
最简单的工作模式,每一个明文块的加密完全独立,互不干涉。
优点:1.简单2.有利于并行计算
缺点:相同的明文块经过加密会变成相同的密文块,安全性较差
- CBC (Cipher Block Chainning)
引入了初始向量的概念(Initialization Vector)。iv的作用有点像MD5的加盐,防止同样的明文块加密成同样的密文块。
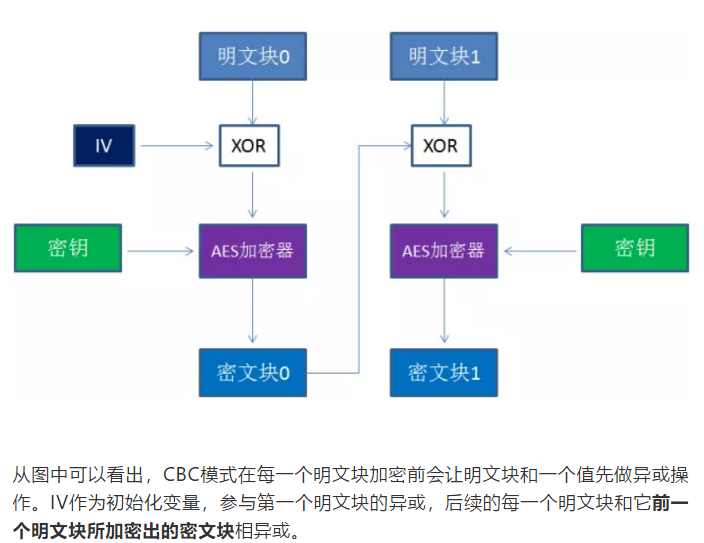
CBC模式在每一个明文块加密前会让明文块和一个值做异或操作,IV作为初始化向量,只参与第一个明文块的异或,后续的每一个明文块和前一个明文块所加密出的密文块做异或,这样相同的明文块,加密出的密文块显然是不一样的。
优点:安全性更高
缺点:1.无法并行计算,性能上不如ECB2.引入初始化向量iv增加复杂度
MD5
可以从任意长度的明文字符串生成128位的哈希值
验签过程
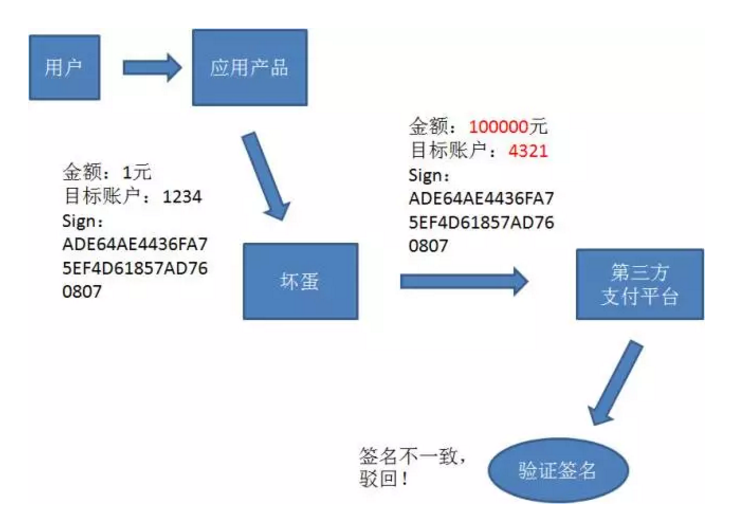
1. 收集相关业务参数,在这里时金额和目标账户。
2. 按照规则把参数名和参数值拼接成一个字符串,同时把给定的密钥也拼接起来,之所以需要密钥,是因为攻击者可能也知道拼接规则。amout=1_acount=1234_key=abcd
3. 利用MD5算法,从原文生成hash值,MD5生成的哈希值是128的二进制,也就是32位的十六进制
4. 发送的时候除了把基本请求参数带上,把sign:ADE876ISHDFAKHDJ也带上
5.第三方支付平台如何验证请求的签名?三步
* 双方约定相同的字符串拼接规则,和相同的密钥
* 第三方平台接收到请求后,按照拼接规则拼接业务参数和密钥,利用MD5算法生成sign
* 生成的sign和请求带过去的sign做对比,如果两个值相同则签名无误,两个值不同则信息做了篡改
密钥本身不直接传输,只参与sign的拼接,如果坏人既知道拼接规则又知道密钥,只能通过业务上的规则来限制,比如最大金额的限制
MD5底层原理
分为四步:处理原文,设置初始值,循环加工,拼接结果 1. 处理原文
首先,计算原文的长度(bit)对512求余的结果,如果不等于448,就需要填充原文使得原文对512求余的结果等于448.填充方法就是第一位填充1,其余位填充0,填充完后,信息的长度就是512*N+448
之后用剩余的位置(512-448=64)记录原文的真正长度,把长度的二进制值补在最后这样处理后的信息长度就是512*(N+1)
- 设置初始值
MD5的哈希结果长度为128位,按照每32位一组共4组,4组是由四个初始向量值A,B,C,D经过不断演变得到,MD5的官方实践中A,B,C,D的初始值如下(十六进制):
A= 0x01234567
B= 0x89ABCDEF
C= 0xFEDCBA98
D= 0x76543210
- 循环加工
最复杂的一步,下图代表了单次A,B,C,D演变的流程
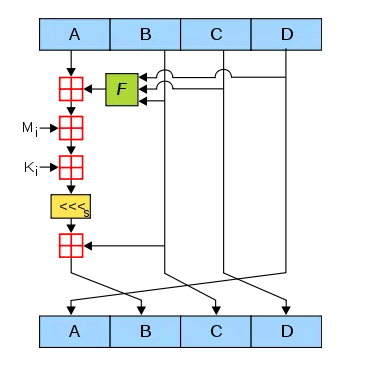
图中,A,B,C,D就是哈希值的四个分组。每一次循环都会让旧的ABCD产生新的ABCD。一共进行多少次循环呢?由处理后的原文长度决定。
假设处理后的原文长度是M 主循环次数 = M / 512 每个主循环中包含 512 / 32 * 4 = 64 次 子循环。 上面这张图所表达的就是单次子循环的流程。
1.绿色F 图中的绿色F,代表非线性函数。官方MD5所用到的函数有四种:
F(X, Y, Z) =(X&Y) | ((~X) & Z) G(X, Y, Z) =(X&Z) | (Y & (~Z)) H(X, Y, Z) =X^Y^Z I(X, Y, Z)=Y^(X|(~Z))
在主循环下面64次子循环中,F、G、H、I 交替使用,第一个16次使用F,第二个16次使用G,第三个16次使用H,第四个16次使用I。
2.红色“田”字 很简单,红色的田字代表相加的意思。
3.Mi Mi是第一步处理后的原文。在第一步中,处理后原文的长度是512的整数倍。把原文的每512位再分成16等份,命名为M0~M15,每一等份长度32。在64次子循环中,每16次循环,都会交替用到M1~M16之一。
4.Ki
一个常量,在64次子循环中,每一次用到的常量都是不同的。
5.黄色的<<<S
左移S位,S的值也是常量。
“流水线”的最后,让计算的结果和B相加,取代原先的B。新ABCD的产生可以归纳为:
新A = 原d 新B = b+((a+F(b,c,d)+Mj+Ki)<<<s) 新C = 原b 新D = 原c
Base64
排序
冒泡算法和优化
int[] arr = {3,7,4,8,1};
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - i - 1; j++) {
if(arr[j]>arr[j+1]){
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}